The Control Plane Was the Point: Revisiting autofz in the LLM Era
Preface
autofz is a meta-fuzzer: a runtime orchestrator for existing fuzzers. I developed it during the first few years of my PhD, and it was accepted to USENIX Security 2023. The paper and GitHub repository are both public.
A few years later, autofz is not one of the most cited fuzzing papers, but its control-plane framing has aged better than I expected.
I want to revisit autofz now because its core question feels more relevant than its original fuzzing context: when you have many imperfect workers, how should a system spend a fixed budget among them?
In 2023, the workers were fuzzers. Today, in CRS and LLM-agent systems, the workers may be fuzzers, static analyzers, code agents, patch generators, validators, or model variants. The surface has changed, but the control-plane question is similar: which worker should run, what evidence should be shared, when should the system switch direction, and when should it stop?
This matters more as security capability becomes cheaper and more widely available. I do not mean that security is solved, or that expert systems no longer matter. I mean something narrower: producing plausible bug candidates is becoming easier. The harder problem is turning noisy candidate generation into reliable evidence, reproducible PoVs, useful patches, and good budget decisions.
That is why I do not think the last decade of fuzzing research should be treated as obsolete. Even when the exact techniques are not reused literally, the field has accumulated hard-won lessons about cheap feedback, noisy evaluation, evidence sharing, and fixed-budget automation. autofz was one small version of that larger orchestration problem.
Why fuzzer selection is hard
The initial observation behind autofz was simple: no single fuzzer is always the best fuzzer. The paper made this concrete with four observations.
First, there is no universal fuzzer. Different fuzzers make different tradeoffs in mutation strategy, scheduling, instrumentation, seed management, and search pressure. In the paper’s motivating example, LearnAFL performed best on ffmpeg, but dropped to sixth place on exiv2. RedQueen also outperformed Radamsa by more than 10x on exiv2 under the same resource budget. That kind of target sensitivity is exactly why “just use the best fuzzer” is not a satisfying operational answer.
Second, the best fuzzer can change during the same campaign. We called this rank inversion. On exiv2, Angora made strong early progress, but LAF-Intel and RedQueen caught up after roughly two hours. Later, another inversion happened between LAF-Intel and RedQueen. A static decision made at the beginning would miss that change.
Third, equal resource allocation is wasteful. Collaborative fuzzing can improve over a single fuzzer by sharing seeds, but if every fuzzer receives the same CPU budget forever, the system still spends too much time on workers that are not currently useful.
Fourth, fuzzing randomness makes offline decisions fragile. Even if an expert finds a good combination for one benchmark run, that guidance may not reproduce for the next workload, the next seed corpus, or even another run of the same target. The selection burden does not disappear; it just moves into benchmark selection, training data, or manual tuning.
This was the practical problem autofz tried to remove. A user should be able to provide a pool of available fuzzers and let the system decide which ones deserve the current budget.
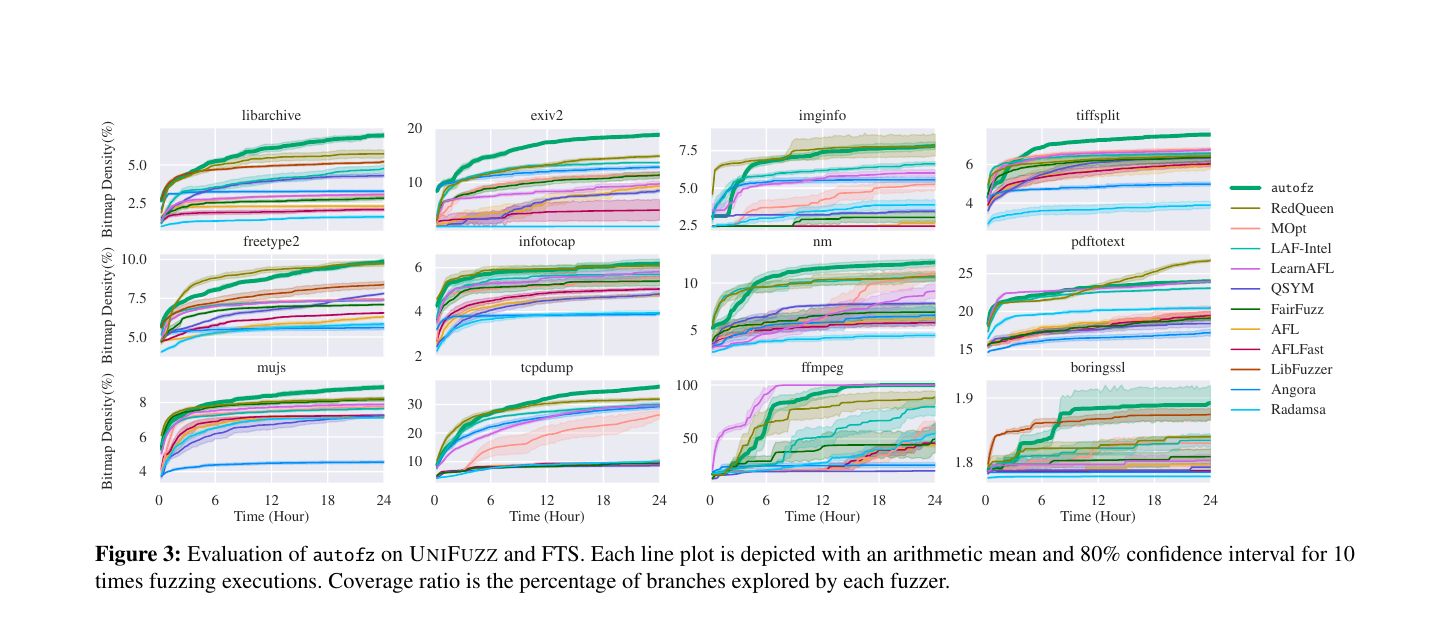
How autofz works
autofz does not implement a new fuzzing algorithm. It runs existing fuzzers and adds a control plane above them.
The control loop has two phases. In the preparation phase, autofz gives baseline fuzzers a short, fair chance to run and observes their progress. Because fuzzers use different internal feedback, autofz maps their interesting inputs back to a common AFL bitmap view. That gives the orchestrator a unified way to compare runtime trends.
The second phase is the focus phase. autofz converts the observed trend into a resource allocation decision. If one fuzzer is clearly ahead, autofz can give the next budget window to that fuzzer. If several fuzzers look useful, it can distribute resources proportionally. Seeds are synchronized across fuzzers so that one worker’s discovery can become another worker’s starting point.
Then the system repeats. It does not assume that the best fuzzer for the previous window is still the best fuzzer for the next one.
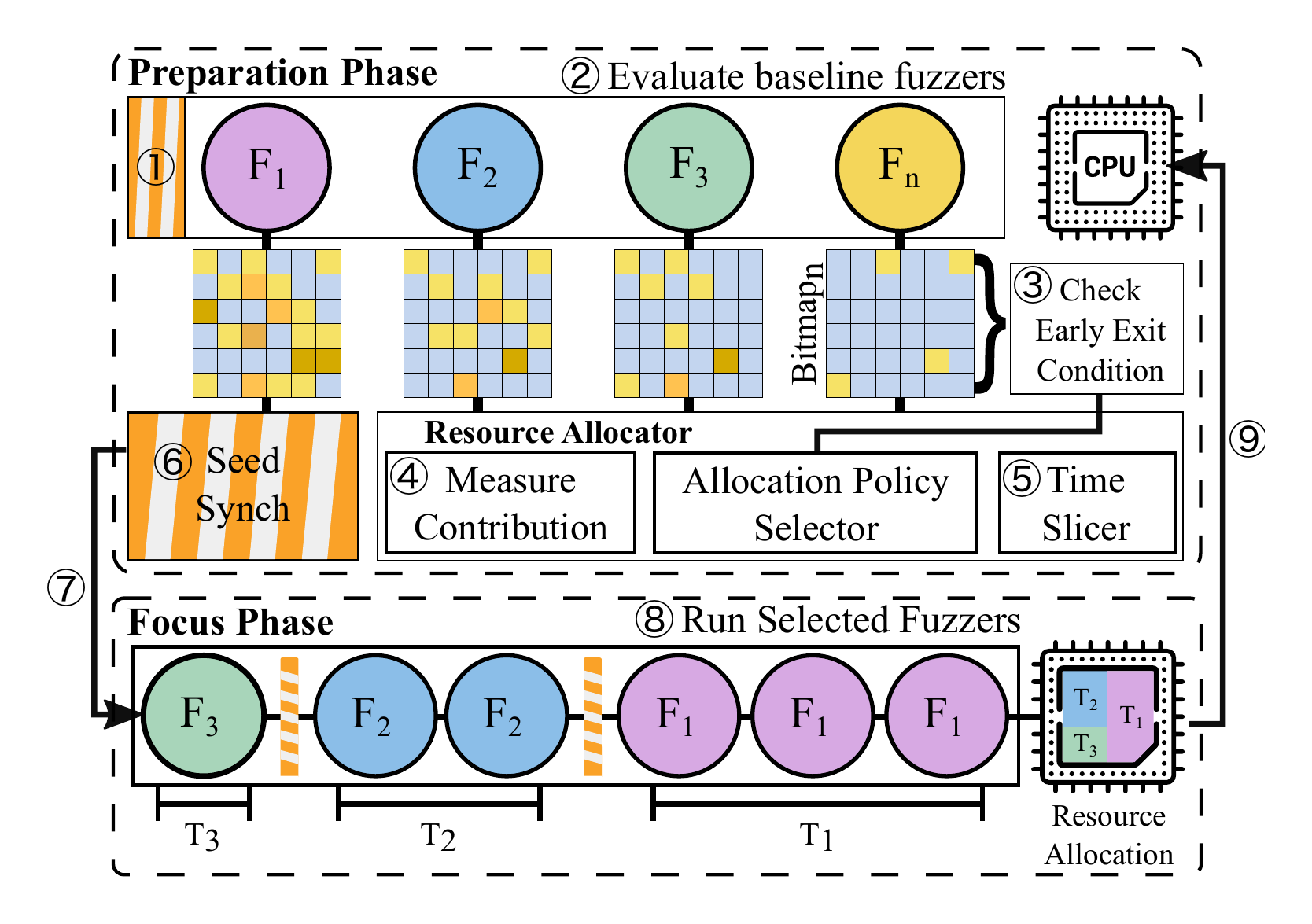
The important phrase from the paper is “per workload, not per program.” A program is not one static search problem. As fuzzing progresses, the remaining branches, useful seeds, and bottlenecks change. autofz tries to react to that runtime workload instead of committing to one fuzzer set for the whole campaign.
The part that took time: making the decisions defensible
The first working prototype beat EnFuzz quickly. Turning that prototype into a paper took much longer because the obvious reviewer question was not “does it win once?” It was “are the scheduling decisions actually good?”
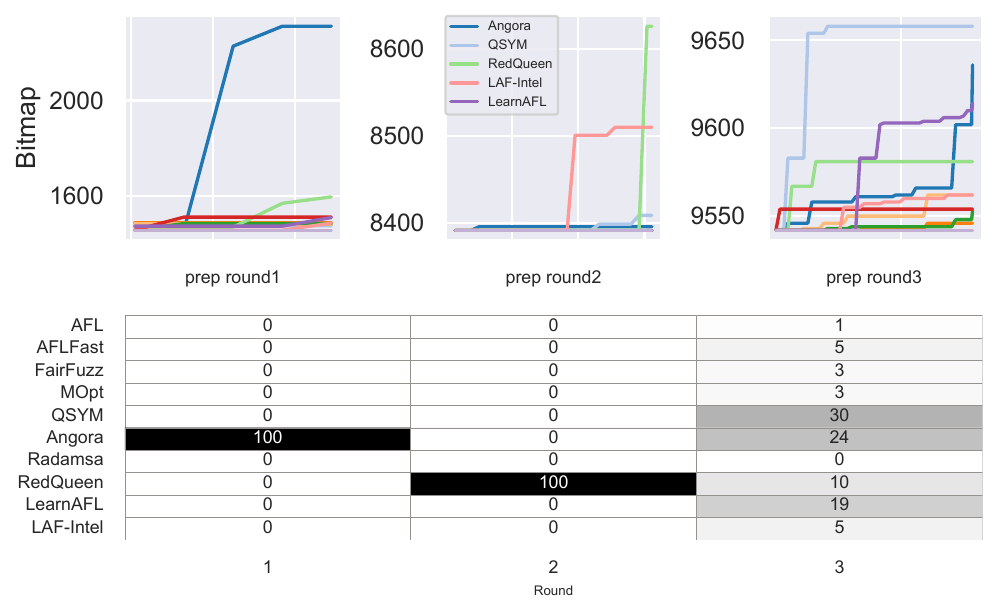
That is why we added the evaluation of autofz’s decisions. For each round, we recorded the point right after the preparation phase and restored the campaign to that snapshot many times. Then we compared autofz’s resource allocation against synthetic decisions that gave the whole focus-phase budget to one baseline fuzzer at a time. This was a way to ask a counterfactual question: given the same starting corpus and the same focus-phase time budget, was autofz’s chosen allocation competitive with the obvious alternatives?
The answer was mostly yes, but with useful caveats. On libarchive, autofz’s decision ranked first in eight of 14 rounds and had an average rank of 2.64. On exiv2, it ranked first in four of 15 rounds and averaged 3.5. That was enough to support the core claim: trends observed during preparation often remain useful for the following focus phase.
The caveats mattered for the paper. When coverage saturates, the choice of fuzzer matters less because no allocation can make much progress. On exiv2, after round 4, different decisions produced very small coverage differences; in one late round, the gap between the best and worst decision was only 0.07% bitmap density. Fuzzing randomness also adds noise even when the comparison starts from the same snapshot. Seed synchronization can further change the next trend: a fuzzer that was not strongest during preparation may become stronger after another fuzzer discovers and shares inputs that unblock it.
This is the part I remember as the real engineering/research gap between a demo and a paper. The prototype showed that orchestration could help. The paper had to explain why a particular scheduling algorithm was reasonable, when its decisions were reliable, and when the signal became weak. We also had to play with the hyperparameters around preparation and focus phases: how long to measure, how quickly to early-exit preparation, how much budget to spend on evaluation instead of exploitation, and how often to revisit the decision. Those details are not glamorous, but they decide whether a meta-fuzzer is actually useful or just lucky on a benchmark run.
Timeline for autofz: from idea to paper acceptance
- Initial idea: around November 2020, though I do not remember the exact date.
- First working prototype beating EnFuzz: around December 2020.
- NDSS 2023: rejected after reaching the second round; it was close. May 2022.
- IEEE S&P 2023: early rejection.
- USENIX Security 2023: minor revision in January 2023, then accepted.
It took much more than a working prototype to turn autofz into a publishable paper, especially while I was still taking courses. In fuzzing research, beating the baseline is not enough. The hard part is explaining why the system wins, when it wins, and what mechanism actually matters.
That was especially true for autofz because it is a meta-fuzzer with many moving parts: the scheduler, the individual fuzzers, seed synchronization, benchmark setup, and resource allocation can all affect the final result.
Previous work: static ensembles vs runtime orchestration
EnFuzz
EnFuzz was the main collaborative fuzzing baseline we compared against in the early prototype. It ensembles multiple fuzzers and lets them share seeds. That is already a useful idea: different fuzzers can benefit from each other’s discoveries.
The limitation is that seed sharing alone is not the whole composition problem. If all fuzzers receive roughly fixed or equal resources, the system still does not answer which fuzzer deserves more CPU at a given moment. In other words, EnFuzz is collaborative, but its resource allocation is still mostly static.
autofz keeps the useful part, seed synchronization, but adds runtime scheduling on top. It treats fuzzer selection and resource allocation as first-class problems.
CUPID
CUPID is another important line of work because it also focuses on combining fuzzers. The difference is when and how the selection decision is made. CUPID uses offline analysis and a training set to predict target-independent fuzzer combinations. That means the selected ensemble is still static during the campaign.
The paper’s Table 1 summarized the difference like this:
| Property | EnFuzz | CUPID | autofz |
|---|---|---|---|
| Number of selected fuzzers | user-configured | user-configured | automatic |
| Typical selected fuzzer set | 2-4 | 2-4 | 1-11 |
| Switches fuzzers at runtime | no | no | yes |
| Requires prior knowledge | yes | yes | no |
| Requires target-specific pretraining | no | partial | no |
| Cost of adding new fuzzers | high | high | low |
| Resource allocation | static | static | dynamic |
| Resource distribution policy | equal | equal | proportional |
| Adapts to runtime workload | no | no | yes |
I would now describe this as a distinction between static ensembles and runtime orchestration. EnFuzz and CUPID are about choosing a useful group of fuzzers. autofz is about repeatedly deciding which workers deserve budget as the workload changes.
The result was not only better coverage. In the paper, autofz outperformed the best individual fuzzers in 11 out of 12 benchmarks and beat collaborative fuzzing approaches in 19 out of 20 benchmarks. On average, it found 152% more bugs than individual fuzzers on UNIFUZZ and FTS, and 415% more bugs than collaborative fuzzing on UNIFUZZ.
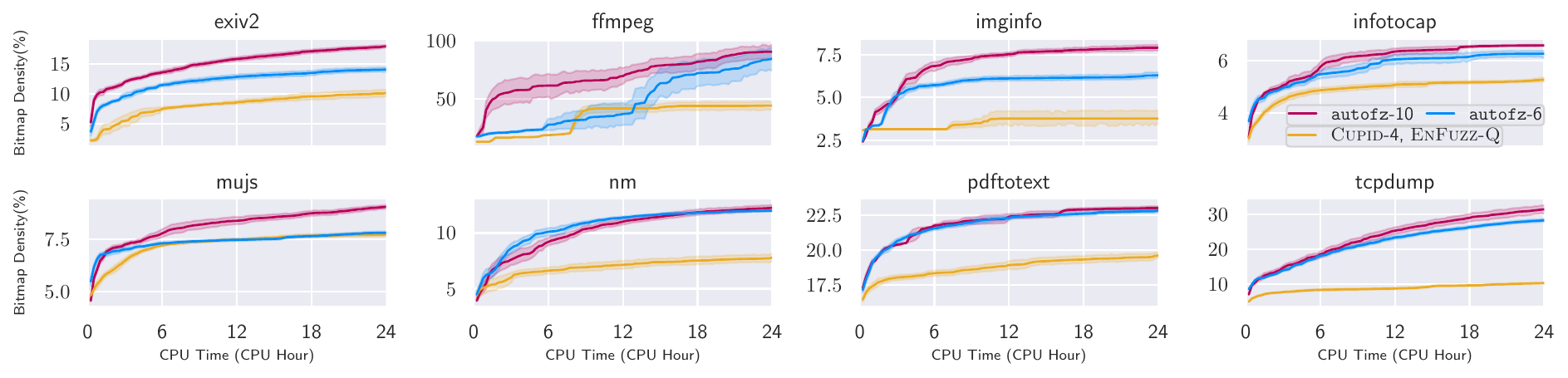
Low-level technique composition vs. high-level fuzzer orchestration
One common question during reviews, and later on Hacker News after the arXiv version, was how autofz differs from AFL++. I think the better framing is to separate two levels of composition.
AFL++ is an excellent example of low-level composition. It combines many compatible fuzzing techniques inside one strong fuzzer implementation. autofz does not compete with that layer. It can use AFL++ as one worker in the pool.
The distinction is that “many techniques in one fuzzer” is not the same as
“orchestrating many workers.” Some features compose cleanly, such as AFL++’s
CmpLog support. Other choices are mutually exclusive per process, such as power
schedules selected with -p. Other workers, such as QSYM and Angora, come with
their own instrumentation and runtime assumptions.
So the two layers are complementary. AFL++ strengthens an individual fuzzer. EnFuzz and autofz work at a higher level: run multiple fuzzers as separate workers, share useful artifacts, and decide which worker deserves resources. autofz’s contribution is in that higher-level orchestration problem: given several existing fuzzers, which ones should run, when should the system switch, and how much resource should each receive?
This distinction is important because both approaches can coexist. A better individual fuzzer makes the pool stronger. A better orchestrator decides how to use that pool under a fixed budget.
Adding fuzzers is not the same as orchestrating well
The same trap shows up in multi-agent systems. Adding more agents can increase diversity, but it also introduces context loss, message-passing overhead, and coordination burden. If the orchestrator cannot decide which agent should own the next step, what evidence should be compressed and shared, and when a thread should be abandoned, the system can spend most of its budget moving information around instead of solving the task.
Fuzzer orchestration has the same shape. Adding more fuzzers is not free: every extra fuzzer creates more measurement cost, more synchronization traffic, and more ways to waste budget on a worker that is currently unhelpful.
The paper evaluated this with an autofz variant that allocates resources equally. The gap between autofz and the equal-allocation variant became clearer as the pool changed, especially when good and bad fuzzers were mixed. In one case study, autofz spent only a small fraction of focus-phase resources on poor-performing fuzzers and shifted most of the budget toward RedQueen, LAF-Intel, and libFuzzer.
That is the point of orchestration: diversity helps only if the control plane can avoid paying full price for every option all the time.
Inspiration for later works
Looking back, the part of autofz that still feels most reusable is not any specific fuzzing heuristic. It is the control-plane idea: watch heterogeneous workers at runtime, compare their marginal progress, and move budget toward the workers that currently look useful.
BandFuzz from Team 42-b3yond-6ug explores a related direction with deep learning and multi-armed bandits. A similar bandit-style idea also appears in RCFuzzer, a recommendation-based collaborative fuzzer from Hanyang University that builds on autofz.
The same orchestration idea also shows up in our own CRS, Atlantis, from Team Atlanta. Atlantis ensembles three CRSs: a C CRS, a Java CRS, and a multilingual CRS, which in practice mainly means C and Java. More technical details, reports, and publications are available from Team Atlanta.
From fuzzer orchestration to agent orchestration
The LLM-era analogy is not that agents are fuzzers. The analogy is that both systems become hard when we stop relying on one worker and start coordinating many heterogeneous workers under a fixed budget.
In autofz, the workers were fuzzers. The shared artifacts were seeds. The cheap feedback signal was coverage. The scheduler watched runtime trends and moved CPU toward fuzzers that looked useful for the current workload.
In CRS and agentic security systems, the workers may be fuzzers, static analyzers, code-reasoning agents, harness generators, patch generators, and validators. The shared artifacts are richer: suspicious commits, static warnings, crashes, generated tests, PoVs, patches, negative evidence, and reviewer decisions. The budget is also richer: CPU time, token cost, wall-clock latency, and human attention.
| autofz world | CRS / agentic security world |
|---|---|
| Fuzzer | Agent, analyzer, harness generator, patcher, validator |
| Seed corpus | Test cases, crashes, PoVs, patches, notes |
| AFL bitmap trend | Shared progress / evidence signal |
| Preparation phase | Exploration / probing |
| Focus phase | Budgeted deepening |
| Seed synchronization | Evidence ledger / blackboard |
| Rank inversion | Best worker changes as context changes |
| CPU budget | CPU + token + wall-clock + reviewer budget |
That makes the orchestration problem harder, not easier. More workers increase diversity, but they also increase noise. If the system cannot decide which worker should own the next step, what evidence should be compressed and shared, and when a direction should be abandoned, it can spend most of its budget moving information around instead of making progress.
The lesson I would carry from autofz is not a particular scheduling heuristic. It is the need for a control plane: a layer that normalizes feedback from heterogeneous workers, compares marginal progress, shares useful artifacts, and moves budget toward the workers that currently deserve it.
What does not transfer directly
The analogy also has limits. autofz had a relatively cheap common signal: coverage trends mapped into a shared bitmap view. Agentic security systems do not get such a clean signal for free. A model’s confidence, a static-analysis warning, a failing test, and a patch diff are not naturally comparable.
The lesson from autofz is therefore not “use the same scheduler.” The lesson is that orchestration only works after heterogeneous workers expose evidence in a form the control plane can compare.
Final remark: is fuzzing research dead?
No. But the role of fuzzing is changing.
A production vulnerability-discovery system will probably look less like “one perfect fuzzer” and more like a CRS: fuzzing combined with static analysis, program understanding, LLM-based reasoning, patch generation, and validation. Fuzzing remains valuable because it is one of the cheapest ways to produce dynamic evidence. Once a harness exists, CPU-scaled exploration is often much cheaper and more repeatable than asking an LLM to invent every input from scratch.
At the same time, recent agentic-security results make it clear that raw bug-finding capability is becoming more available. General coding agents can already produce useful vulnerability candidates on realistic challenge repositories. The RunSybil AIxCC reproduction is a good example: general-access models did surprisingly well at vulnerability detection, but the remaining hard parts were exactly the systems problems: prioritization, false-positive control, reproducible PoVs, validated patches, and budget allocation.
That is why autofz still feels relevant to me. Its specific workers were fuzzers, and its feedback signal was coverage, but the deeper problem was a control-plane problem: how to coordinate heterogeneous workers under a fixed budget.
The next generation of agentic security systems should borrow the reusable lessons from fuzzing research rather than treat it as old work. Not every idea needs to survive as a standalone fuzzer technique. The reusable lessons are broader: how to build cheap feedback loops, how to evaluate noisy systems, how to share evidence across workers, how to compare tools under a fixed budget, and how to turn a clever prototype into a reliable system.